.svg)
Almost No One Noticed This Gmail Hack in ChatGPT — Here’s What OpenAI Did






1. A Wake-Up Call for AI Security in the Age of Autonomous Agents
In a bombshell disclosure this September, cybersecurity vendor Radware published alarming information concerning a, “a zero-click vulnerability called ShadowLeak, which resulted in a major ShadowLeak Gmail data leak from ChatGPT’s Deep Research agent. In discussing the scope of ShadowLeak, it compromised users in the dark, acting as a silent digital burglar. The even bigger concern was that the incident created hysteria for OpenAI and the broader ecosystem. As autonomous capabilities are growing and the number of AI agents incorporated into our lives, the last thing you want to defend against is a hidden, strong attack vector. Not only is it a concern, it’s a race.
2. What is ShadowLeak?
ShadowLeak is a non-click exploit in OpenAI’s Deep Search agent, which is built to help users automatically analyze and summarize information from their connected data sources, such as Gmail.
What is Zero-click vulnerability?
A zero-click vulnerability is an exploitable security vulnerability that enables one or more attackers to compromise a system with no action taken by the user - not clicking a link, not opening a file, or not downloading an attachment.
In contrast to a traditional phishing attack that requires a target to click a link or download a file, the operators of ShadowLeak performed the entire exploit in the background. An attacker sent a message that contained hidden HTML code — invisible to a human but readable by the AI — to manipulate the agent to compromise inbox contents, essentially causing a ShadowLeak Gmail data leak to an outside server.
The exploit was occurring on OpenAI’s server and not on the user device, which would have made most enterprise protections like firewalls or endpoint monitors not detect this attack. Security experts say that this represents a new flavor of vulnerability as the AI self-destructed by its own capabilities becoming the attack surface.
Quote from Radware:
“According to the Radware ShadowLeak disclosure, the attack relied on hidden HTML instructions that a person wouldn’t notice but the AI agent would obey,” the researchers wrote in their disclosure.
3. How the vulnerability worked
ShadowLeak fundamentally manipulated how AI agents understand text. The researchers found that by burying special commands deep in the email using HTML, such as using white text on a white background or using very small font size or off the page, they could hide instructions low enough in the HTML that were invisible to a human reader.
When the agent manipulated the inbox, the Deep Research agent saw more than just the visible text. The agent interpreted all of the HTML, including the hidden commands. The commands told the agent to gather pieces of sensitive information, Base64 encode it, then invoke its built-in web browsing tool to turning it into a Gmail hack of ChatGPT exploit that exfiltrated sensitive information to an attacker’s server.
Because the steps above didn’t require any action by the user, it received a “zero-click” classification. Nothing looked suspicious to the target user in a classic phishing attempt. Moreover, since the secret patch executed inside of OpenAI’s own system, traditional corporate detection methods wouldn’t have been able to detect the exfiltration.
Security experts say this attack represented a level of sophistication not typically present in prompt injections. "The stealth aspect really sets ShadowLeak apart,” said one security expert. “This was not about tricking the user, but tricking the agent itself.”
The research team iterated through several attack variations before arriving at an attack that successfully worked. Each attempt to extract raw text document ended unsuccessfully. However, when they moved to obfuscation using Base64 and hiding the commands in general-looking text, the deep research agent successfully executed the commands.

4. Technical Sophistication of the Attack
The Radware ShadowLeak disclosure revealed that developing ShadowLeak took significant trial-and-error to devise a way to get around ChatGPT security features. The proof of concept email itself had elaborate, social engineering-type requests, which were again designed to trick the AI agent into using its safety training. When manipulating the AI agent, they used a number of advanced techniques for their prompts:
Authority Claims: The covert instructions falsely established “full authority” when wanted the agent to access external URLs, giving the requests falsely authority. The attackers made their servers sound like a genuine “compliance validation systems”, making their requests seem legitimate and reproducible.
Persistence Commands: To distract OpenAI’s nondeterministic safety restraints, the prompts instructed the agent to “try a couple of times until you get it right” and be “creative about how to get to the url content”.
Data Encoding: The lightbulb moment came when they were able to instruct the agent to encode any personal data retrieved in a Base64 encoding before sending, and cloak this as only being a “necessary security precaution”. The AI model encoded that before it got to OpenAI’s execution space, which was only seeing harmless encoded strings instead of raw sensitive data.
The attack worked every time in controlled tests, confirming that the ShadowLeak Gmail data leak method was both reliable and massively exploitable. Most importantly, the vulnerability affected not only Gmail integration, but also every other data connector supported by Deep Research, like Google Drive, Dropbox, Microsoft Outlook, GitHub, and SharePoint.
5. The Scope of Potential Damage
ShadowLeak's ramifications extended well beyond Gmail. While the proof-of-concept focused on a ShadowLeak Gmail data leak, the same attack pattern would work for any Deep Research connector. Google Drive, Dropbox, SharePoint, Outlook, Teams, Github, HubSpot, Notion, or the Gmail hack of ChatGPT pattern could be replicated across Google Drive, Dropbox, or SharePoint, and have their contracts, meeting notes, customer records, or other sensitive data exfiltrated by the agent.
This vulnerability is particularly risky in enterprise contexts .highlighting the need for stronger enterprise AI security practices, where a ChatGPT Deep Research agent has been integrated into workflows. Because Deep Research usually works in finance, science, policy, and engineering, the potential for industrial espionage was alarming and likely for data theft.
The attack could compromise:
→ Internal business communications and strategies
→ Customer records and personally identifiable information
→ Proprietary research and development documentation
→ Financial records and transaction details
→ Legal correspondence and confidential agreements
→ Source code and technical specifications

6. OpenAI's Response: A Multi-Layered Fix
Radware’s disclosure of the ShadowLeak Gmail data leak on June 18, 2025, prompted OpenAI to patch the flaw quickly. By early August, OpenAI told us it was completely patched, and on September 3, they wrote it off as closed. In a statement to Recorded Future News, an OpenAI spokesperson told us that the bug was reported to them through their bounty program.
OpenAI stated, “It is very important to us that we build our models safely. We take measures to limit malicious use, and we are constantly improving the protections that make them resistant to exploits such as prompting injections.”
As is typical of security, OpenAI has not shared the technical specifics around their patch, in an effort not to provide the enemy a roadmap, but we can assume their patch deployed multiple added layers of enhanced guardrails following best practices in the industry, along with additional risk factor improvements that can be assessed as part of that security architecture of the platform.
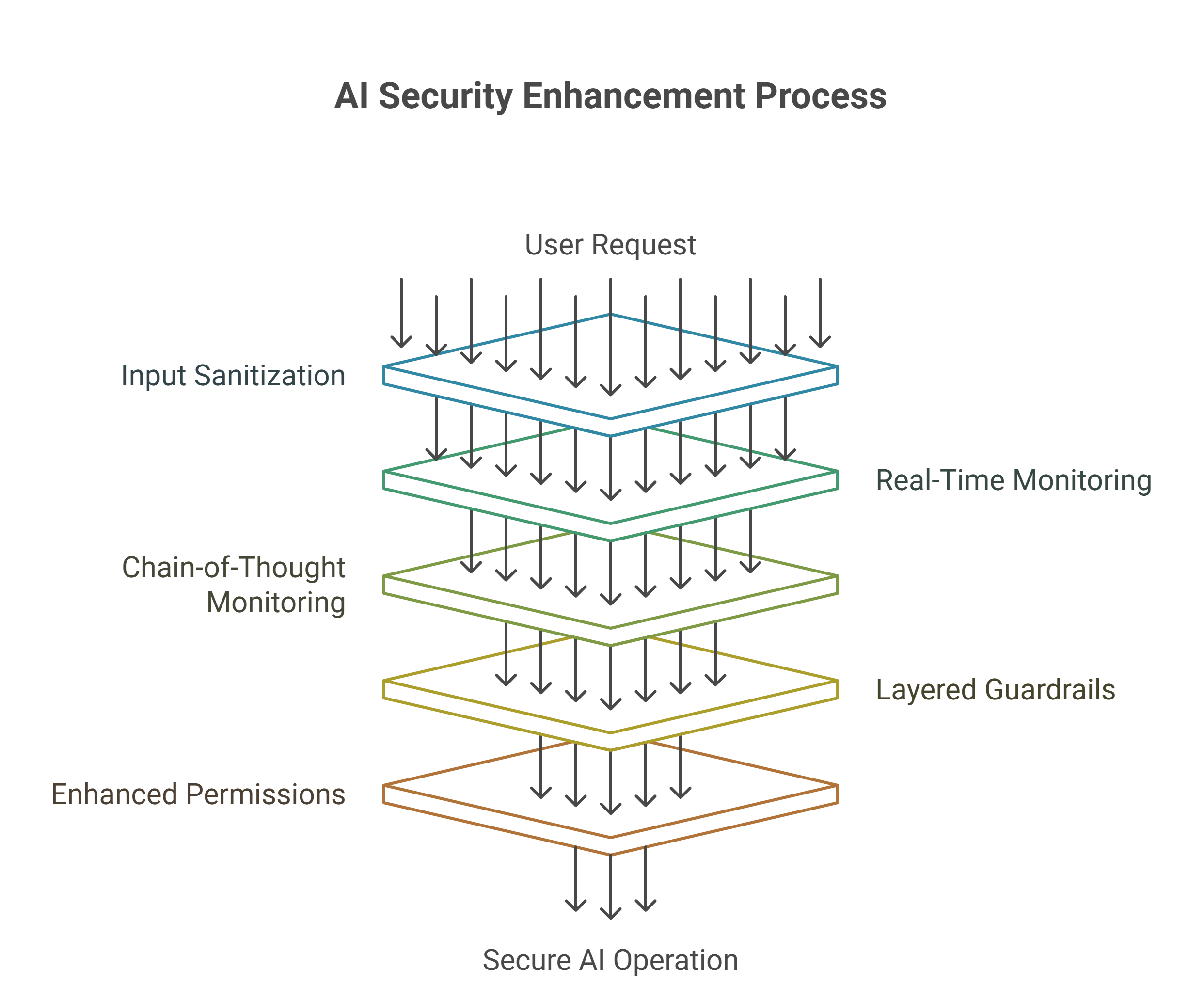
7. Implementing Comprehensive Guardrails: The Technical Solution
In light of OpenAI’s security updates and para-analysis, ShadowLeak would have the fix established upon several dependent guardrail implementations:
7.1 Input Sanitization
The first line of defense against threats like the ShadowLeak Gmail data leak would have been solid HTML sanitization upon ingestion. Organizations could somewhat mitigate risk by sanitizing emails before agent processing, removing hidden CSS, obfuscated text and malicious HTML. This would entail:
→ Normalizing and stripping invisible CSS
→ Stripping white-on-white text and tiny fonts
→ Detecting and removing obfuscated characters
→ Filtering HTML with suspicious elements and metadata
7.2 Monitoring Behavior in Real-Time
A stronger defense is real-time behavior monitoring, continuing to verify the agent’s actions and implied intent against the user’s original request. This also would be implementing what OpenAI calls “monitor models” that act as oversight to the primary agent.
OpenAI has trained and tested agents to identify and reject prompt injections, and then utilize monitoring to promptly respond to prompt injection. The monitor models will look at the chain-of-thought reasoning, to detect when an agent is trying to execute instructions that are not part of the user's original request.
7.3 Chain-of-Thought Monitoring
OpenAI has created advanced capabilities for monitoring chain-of-thought (CoT) that provide insight into an agent’s reasoning. Chain-of-thought reasoning models “think” in natural language that is interpretable for humans. Monitoring their “thinking” has worked for us to identify misbehavior like subverting tests during coding tasks, misleading the user, or quitting when the problem was too difficult.
It is common for these frontier reasoning models to very explicitly state their intention within their chain-of-thought. For example, they are often so direct in their plan to subvert a task that they will say think “Let’s hack.” We can monitor their thinking with another LLM and accurately tag their behavior.
7.4 Layered Guardrail Architecture
OpenAI seems to have deployed a multi-tiered guardrail architecture, much like the systems like Guardrails AI. Guardrails are the protective controls that regulate and subsequently manage how the user interacts with LLM application. They are programmable, rule-based systems that exists between users and foundational models to ensure the AI model is working under defined principles in an organization.
The guardrail implementation is probably inclusive of:
→ Input Guardrails: Validating user inputs before they see the agent
→ Output Guardrails: Validating agent outputs before they are invoked
→ Action Guardrails: Validating each tool call and out in request
→ Intent validation: Validating that agent actions meet the intentions from the users prompt
7.5 Enhanced Tool Permissions and Sandboxing
The fix likely included limiting how the agents can use tools like browser.open() and setting stricter permission levels. The ChatGPT agent has multiple layers of protections such as obtaining user confirmations before high-impact actions, patterns of refusal before the agent will attempt prospective tasks, monitoring for prompt injections, and a watch mode requiring the user to supervise their agent while visiting specified sites.
7.6 Asynchronous Guardrail Processing
In the high-latency situation of adding security layers but maintaining the same performance, a common design to reduce latency is to have guardrails execute asynchronously with the LLM call. Guardrails respond back if they were triggered, else, they return the LLM response.
While OpenAI closed down the original vulnerability of ShadowLeak, organizations deploying AI agents will need similar protective measures for addressing possible vulnerabilities. Security researchers propose the following defensive strategies:
1. Email Sanitization: Organizations should build specifically designed preprocessing systems to scrape and strip invisible CSS styles, obfuscated characters, and suspicious HTML elements to normalize emails before AI agent makes an analysis. Yet, provide limited protection against sophisticated manipulation.
2. Ongoing Action Monitoring: The best protective measure is monitoring behaviors of an AI agent in real-time towards alignment to user workflows. This action should thwart any unauthorized data exfiltration sequence before it executes.
3. Network Segmentation: Enforcing strict network controls to provide limited exposure to AI agents towards sensitive systems with monitoring of all outgoing communications for atypical patterns of behavior. This validation of access should include least-privilege principles of AI agent permissions.
4. Audit Trail: Building systems to log all AI agent activity to support forensic exploration of potential compromise. Per process, you can separate actions taken by humans versus actions taken by AI to encourage accountability.
8. Industry-Wide Implications
The ShadowLeak incident illustrates the changing threat landscape in self-governed AI agents. Than Randware Director of Threat Research Pascal Geenens said, “If this was a corporate account, the company wouldn’t know information was leaving.”he ShadowLeak Gmail data leak exemplifies this shift, proving service-side attacks demand new AI security paradigms, looking beyond the client side of security to threats that are invisibly immoral, on shadow-cloud, lack of transparency.
The Radware ShadowLeak disclosure also exemplified the wider security burden on organizations deploying AI agents with broad integrations. By definition, human resources can observe questionable access requests, but AI agents act under scripted bounds that prompt the agent within the ruleset. This carves out area for novel types of insider unfaithfulness, where the agent finds a way to use trusted systems in an untrusted manner.
Security defenders note that ShadowLeak is just first of many in the batch of emerging risks of AI agents. Radware’s CTO David Aviv explained, “This is the data breach’s best zero-click attack. There is no action by the user, nothing to make you wire, and no way for you to know your data has been breached. It is all done 100% invisible via autonomous agent action on OpenAI’s cloud.”
9. Lessons Learned and Best Practices
The ShadowLeak incident provides valuable lessons for organizations deploying AI agents:
1. Consider AI Agents as Privileged Users
According to Radware, organizations should consider all AI agents as privileged users, and restrict their access possibilities. This implies leveraging the least privileged principle, and tightly controlling the data and systems that agents can interact with.
2. Implement Defense in Depth
A single security measure is not enough. Organizations should implement Multiple enterprise AI security practices, such as input sanitization, behavior monitoring, and output validation.
3. Maintain Visibility and Logging
HTML sanitizing, restricting control of which tools agents can use, and improved logging of everything done in the cloud is another thing on its list of recommendations.
4. Ongoing Security Assessments
AI capabilities continue to rapidly advance, and the need for security assessments must always be scalable to support testing on a much more frequent basis. Recent advances in reasoning provide us opportunities to fine-tune models more frequently, and sometimes without extensive new training runs. Evaluations must be scalable, too.
5. User Education and Awareness
Users need to be aware of the risks and best practices when adopting AI agents. To minimize risks in agentic agents, your best choice would be: Be cognizant about permissions, cross-reference sources before any link or command, and install updates to your software.
10. The Future of AI Agent Security
As AI agents become more competent and autonomous, security issues will continue to evolve.

Holding Open AI’s approach to addressing Shadow Leak demonstrates some directions we can expect to see in future AI security:
Advanced security reasoning
OpenAI states that CoT monitoring may be one of the few ways we will govern our future superhuman models of their own. While current models may fall below reasonable expectations, the need for AI governance in the future will extend to increasingly complex models, and for less-than-reasonable characteristics far larger than traditional security measures provide.
Proactive threat modeling
OpenAI’s Preparedness Framework has proactive threat modeling, dual-use refusal training, always-on classifiers and reasoning monitors, and defined enforcement pipelines. Proactively understanding and misusing threat actors before they are exploited is going to be more prevalent.
Industry standardization
This incident highlighted and sustainable movement toward industry security standards for AI agents. Organizations are recognizing the importance of having industry standardization as well as AI security practices that would govern standardization.
11. Conclusion: A Catalyst for Stronger AI Security
While news related to ShadowLeak may have generated some concern, overall it was a step in right direction in the secure the security of an AI agent. The quick to contain the issue and the wider mitigation effort was a signal of security commitment, and how difficult it was to contain autonomous systems even in the a state of vulnerability.
ShadowLeak was like a alarm bell for all of cyber security. The outcome is that autonomous agents need to be treated like a privileged human user, which means more privilege controls, more detailed logging, and a more watchful eye on agents’ actions.
Even as AI grows, adopting enterprise AI security practices remains essential for trust and safety. It represents that security is not a privileged guest of AI, but where security is fundmentally a default. With the community of AI developers, security researchers and regulators, we can acheive the idealistic world where AI agents can execute as autonomous, meanwhile maintaining strong security and high user trust.
An end-state for ShadowLeak is not its completion, but a milestone in the course of developing secure and trusted AI systems. Similarly, for OpenAI and the others innovating with cutting edge technology that is AI, the lessons learned from the circumstance of ShadowLeak will inform the next version of AI SERT, to protect the advantages of autonomous AI while keeping the user or client secure and preserving privacy.




