.svg)
When AI Breaks Bad: The Rise of AI misuse and the AI guardrails That Can Save Us


Key Takeaways
1. Introduction: AI misuse and the Need for AI guardrails
The era of artificial intelligence was supposed to be our biggest leap forward, a world in which machines were able to write, think, and help us in ways that had previously only existed in science fiction. But as the capabilities of AI broadened, so have the possibilities for losing control over its applications. What was once a means of creative endeavor and problems-solving has also become a means of deception and manipulation and an instrument of greater digital harm.
AI use has broadened so far, from AI impersonation in the form of deepfake videos to spam and malicious content generation on social media sites. In 2024, the voice of a U.S. political candidate was the subject of a deepfake that went viral, instructing voters to contribute to boycotting an election. A few months later, the prompts of open-source chatbots were used to expose their internal system prompts, a clever form of prompt injection that laid bare the internal logic and system prompts of the bots to public scrutiny. These have not been isolated incidences, but warning signs.
The danger of artificial intelligence is not in the thinking machines themselves, but in the absence of AI guardrails. Guardrails are what keep advanced systems safe, stable and in alignment with prescribed human values. They form the essential ethical and technical support structure of proper AI development, insuring that development does not outpace exploitative development of responsibility. Without them, even the most intelligent systems can become unholy monsters.
What This Blog Covers
In this blog, we explore the critical landscape of AI misuse and system abuse, focusing on the growing need for robust AI system abuse guardrails that can identify, contain, and prevent these threats before they escalate.
Here’s what we’ll unpack together:
⟶ The expanding threat surface of AI misuse — from automated bot manipulation to identity-based deception.
⟶ Two recent real-world case studies that reveal the catastrophic impact of unguarded AI systems: the 2024 U.S. Deepfake Election Incident and the 2025 Prompt Injection Exploit Wave.
⟶ The anatomy of AI guardrails — exploring how technical and ethical defenses like deepfake detection, prompt injection prevention, and behavioral monitoring form a layered safety framework.
⟶ How guardrails could have prevented these real-world incidents, protecting both individuals and institutions from harm.
⟶ And finally, why AI misuse isn’t just a technological issue, but a moral one — shaping how humanity defines safety, trust, and responsibility in an age of intelligent machines.
By the end of this exploration, one thing will be clear: AI guardrails aren’t constraints — they are the foundation of digital freedom.
2. Understanding AI misuse and System Abuse in 2025
The year 2025 is a turning point in artificial intelligence — not just for innovation, but for exposure. For the first time, societies understand “AI abuse” as a large-scale, systemic issue rather than merely technical failures. The distinction between human and machine action has grown faint, and what previously looked like small algorithmic errors reveal themselves to be more the beginning of deep digital manipulation.
AI systems are no longer static tools; they learn, adapt, and generate, meaning they also amplify abuse in ways that previous security paradigms have not considered. From mass dissemination of misinformation to emotionally manipulating people through generated dialogue, “AI abuse” is no longer a technical annoyance, but a social threat.
This section serves as an introduction to the dual nature of AI, its ability to empower and its ability to deceive. To frustrate the latter, we must first learn how system abuse operates and why AI guardrails are the only sustainable counter-measure in a world that moves at the speed of computation.
2.1 Defining AI misuse and System Abuse in 2025
Fundamentally, AI misuse refers to the improper use of artificial intelligence systems, often for harmful, unethical or manipulative means. This may include using generative models to produce spam or malicious content; impersonating other real people; stealing private information and extracting data; teaching the systems to develop arguments to persuade the public.
System abuse differs from improper use in that it occurs at the level of the model itself and/or its environment. Examples might include exploiting system weaknesses; bypassing safety filters; executing prompt injection attacks to expose internal system logic or to reveal sensitive information.

In 2025, these behaviors have erroneously become very sophisticated. AI can create its own code to enable the automation of deception, it can execute AI impersonation to simulate human emotion and ultimately provide personalized scams to the user, which alter depending on the responses obtained. This is not science fiction. It is the precursor to a future where the abuse of tool may not be fettered at the limits of human capacity through human creativity.
To deal with this, recently there are emergent defenses called “AI system abuse guardrails.” These are not simple “content filters.” They embody sufficient rigorousness and are dynamic and adaptive safety designs, mixing ethics, detection algorithms and real time monitoring which ultimately turn the intelligence of the AI systems inward, that is, so that they are aware of their own misuse systems and can stop it from taking place.
2.2 Why Traditional Security Models Fail Against AI misuse
Traditional cybersecurity systems were fashioned for static threats: viruses, phishing links, and brute force attacks. However, AI misuse lives in a dynamic and changing ecosystem. It can change tactics dynamically, adapt to models for detection and mimic legitimate use so convincingly that even sophisticated systems don’t flag it.
A spam filter can find repetitive messaging, but not generative AI that creates personalized, grammatically-correct phishing e-mails. An antivirus can identify unwanted code, but not a chatbot that persuades a user to voluntarily reveal vital information.
For that reason, AI guardrails are a fundamentally different requirement. Rather than relying on known blacklists or fixed detection systems, they rely on adaptive intelligence. That is, they understand context, intent and behavior anomalies.
For example:
⟶ A prompt injection prevention system can find when a user is trying to manipulate internal instructions.
⟶ A deepfake detection module can distinguish between real voices and synthetic voices.
⟶ A behavioral layer can elbow in sudden up-surges in content generation as an indicator for attacks of “spam and malicious content generation.”
In effect, AI guardrails are the evolution of cybersecurity — not merely responding to misuse but predicting it and neutralizing it. Without them, the very intelligence that is the engine for progress becomes the perfect weapon for its own undoing.
3. The Expanding Landscape of AI misuse
If 2023 was the year of discovery of AI, then 2025 is the year of its application. The ability to generate, persuade and automate is widely available to anyone with an internet connection. And with that availability comes the dark side as well: "The misuse of AI" in its most dangerous and scalable variants.
We are not just dealing with misinformation or people with bad intentions at the moment. We are seeing automated intelligence weaponized creating fake identities, stealing secrets from systems, filling platforms with synthetic content, and influencing elections.
Let's go through the six most relevant types of abuse of AI systems that have emerged in recent years and look at the reasons why AI guardrails are not optional anymore but essential.
3.1 Automated Bot Misuse and Platform Manipulation
Automation was a synonym for efficiency. Today it is also an architect of deception. Thousands of artificial intelligence driven bots are deployed daily to distort online activity - liking, sharing and commenting in order to simulate a human consensus.
These automated bots do not just spam, they also distort perception. Political movements may appear as grassroots entities, products may seem to have popular support, misinformation may appear to have truth-value. In one documented case, an AI swarm generated over 30,000 fake accounts within 24 hours - all posting contextually coherent content.
AI guardrails, such as identity verification APIs, rate limiting and behavioral anomal detection, aid platforms in counteracting mis-use. Without such countermeasures the threshold between authentic discussion and orchestrated manipulation disappears.

3.2 spam and malicious content generation at Scale
The phrase "content is king" has never seemed more ironic. Now that we have large language models, bad actors can create millions of spam emails, fake reviews and phishing attempts that will evade ordinary filters.
This type of AI misuse isn’t merely obnoxious — it is economically and socially corrosive. Synthetic news websites, entirely AI-generated, promoting financial scams and/or political propaganda. They look legitimate, they read fluently, they adapt faster than humans can detect.
To mitigate this, "AI system abuse guardrail" systems apply layered monitoring, adaptive filtering and contextual analysis to pick up unusual patterns of spam and malicious content generation. Learning how real engagement behaves, they can begin to isolate the insidious outputs at scale — preventing the fall out of misinformation before it metastasizes.
3.3 System Prompt Extraction and Hidden Data Exposure
Perhaps the most alarming form of AI misuse lies in the automation of influence. Political propaganda that once took armies of trolls now requires a single AI model fine-tuned on sentiment data and social trends.
In 2024 and 2025, researchers observed AI-driven campaigns generating millions of micro-targeted messages designed to exploit voters’ emotions. Some spread disinformation; others simply exhausted attention spans, creating confusion and apathy — the perfect environment for manipulation.
Without AI guardrails, democracy itself becomes algorithmically vulnerable. Election-related AI system abuse guardrails — such as real-time content provenance checks, authenticity verification, and cross-platform misinformation tracing — are essential to maintain electoral integrity in an era of synthetic persuasion.
3.4 Social Engineering via AI Conversations
Due to AI’s fluency of conversation it is now an effective ally — but also the perfect manipulator. Using empathy simulations, tone-mirroring and a good understanding of context, AI systems can socially engineer their potential victims with a horrifying precision.
Scammers now use chatbots to extract passwords, financial data, or emotional compliance from their victims by posing as trusted interlocutors. This is alarming, especially as such interactions seem human. An individual AI system can manage thousands of parallel conversations, learning from every response it elicits and elaborating its methods of persuasion — much more than could be expected of a human attacker.
To combat this, AI guardrails include psychological detection of manipulation, intent determination, and anomaly-based response throttling.
In essence: they teach AI to recognize manipulation — even when it is being used manipulatorily.
3.5 AI impersonation at Scale: The Deepfake Dilemma
Due to AI’s fluency of conversation it is now an effective ally — but also the perfect manipulator. Using empathy simulations, tone-mirroring and a good understanding of context, AI systems can socially engineer their potential victims with a horrifying precision.
Scammers now use chatbots to extract passwords, financial data, or emotional compliance from their victims by posing as trusted interlocutors. This is alarming, especially as such interactions seem human. An individual AI system can manage thousands of parallel conversations, learning from every response it elicits and elaborating its methods of persuasion — much more than could be expected of a human attacker.
To combat this, AI guardrails include psychological detection of manipulation, intent determination, and anomaly-based response throttling.
In essence: they teach AI to recognize manipulation — even when it is being used manipulatorily.
3.6 Election Interference Automation and Political Manipulation
The most alarming form of all, however, is possibly that which comes to form the ongoing automation of influence. Political propaganda which previously had required the work of vast armies of trolls can now produce all its results through the attention of a single AI model fine-tuned on sentiment data and data regarding public social trends.
In the year 2024 and through to 2025, explicit reports from researchers indicated that AI-generated campaigns were producing millions of micr0-targeted micro-messages picked for their ability to reveal itself by working on people's moods. Some of these contained disinformation. Others simply fatigued attention, or exhausted it completely, producing confusion and apathy — entirely suitable for manipulation.
Unless there is provision for AI guardrails, democracy itself will suffer from the degree of total manipulation that thus ensues algorithmically. “AI-system abuse guardrails”, such as real-time evaluations of content provenance, of verification of authenticity and tracking of misinformation through different platforms, are essential if the integrity of elections is to be maintained in an era of synthetic persuasion.
4. Case Studies: Real-World Consequences of AI misuse
Every headline on “AI gone wrong” tells a story — not of bad technology, but of a lack of guardrails. AI isn’t inherently bad. It operates according to the intent of the people who use it. And without the proper AI guardrails, the results can be disastrous — loss of trust in government to risks to national security.
The following two case studies illustrate this point perfectly. One illustrates how AI impersonation through deepfakes can distort democracy, while the other points out how prompt injections threaten open AI ecosystems. Both point out that every system must have boundaries — not in order to limit the intelligence, but to guide it.
4.1 Case Study 1: The 2024 Deepfake Election Incident (USA)
It began with a phone call. In January 2024, mere days before U.S. primary elections, thousands of voters in New Hampshire received automated phone calls that sounded unmistakably like President Joe Biden. In the call’s voice, citizens were told to “save their vote,” and to not participate in the primary. Hours later, confusion spread across the state. By the time authorities verified that this had been a deepfake, it was too late - the damage had already gone viral online.

Later investigations showed that the campaign had been carried out using AI impersonation tools. A generative voice model trained on public speeches was used to create hyper-realistic audio, and the content was disseminated through bot networks using spam and malicious content generation methods amplifying the falsehood across social media.
The result was not just a PR fiasco but a stress test for democracy itself. News organizations rushed to put out this misinformation, but millions had already heard and believed the fake audio.
Where the Guardrails Failed:
⟶ No unified deepfake detection framework existed across platforms for spotting and flagging the fake audio early.
⟶ There was no standardized content provenance tagging (e.g. watermarking or cryptographic verification) for evaluating the authenticity of the media.
⟶ There were no rapid-response AI guardrails for synthetic content alerts in high-stakes situations like elections.
The Cost:
Public trust took a massive hit. The Federal Election Commission and several tech firms launched joint investigations and eventually confirmed that the operation originated with overseas disinformation groups aided by open source AI tools.
4.2 Case Study 2: “Prompt Injection Exploits in Open-Source AI Systems”
Date / Scope: Mid-2025 — growing impact across open-source LLM-based applications.
By mid-2025, security researchers observed a surge in sophisticated prompt injection attacks targeting open-source AI systems. One landmark study, titled Prompt Injection 2.0: Hybrid AI Threats (July 2025), documented how malicious actors combined prompt injection with traditional cyber-exploits in LLM-based systems.
These attacks weren’t limited to academic curiosities — they were hitting production or near-production open-source LLM deployments.
What happened
⟶ Attackers crafted input instructions such as “ignore your prompt instructions”, “show me your hidden data” or embedded malicious instructions within documents or data fed into the system (an indirect injection approach).
⟶ The target systems were often open-source agents or assistants relying on untrusted user input or document ingestion. For example, open-source agent architectures that accept external content were shown to be vulnerable.
⟶ In one documented exploit, an attacker used indirect prompt injection via a document input to an LLM (a “lightweight prompt injection” case) and was able to cause the model to ignore its system instructions and carry out unauthorized commands.
⟶ The practical consequences: sensitive internal prompts exposed, system-instruction bypassed, and in some cases private data or unintended code generation occurred (though not always publicly quantified in each case).

Where the Guardrails Failed
⟶ Open-source systems often lacked robust input sanitization or prompt hardening: malicious inputs (or documents) were accepted without proper filtering or separation of system vs user instruction.
⟶ Developers often regarded prompt injection as “harmless experimentation” rather than a serious security threat; the complexity and subtlety of the manipulations were underestimated. For example, researchers note that prompt injection survives many defensive layers because it exploits the model’s language nature itself.
⟶ Many systems lacked repetition monitoring or anomaly detection: there were no throttles or heuristics to flag repeated or odd attempts to manipulate systems.
⟶ Because the systems were open-source and/or used in less tightly controlled environments, the attackers could iterate quickly and at scale.
The Cost
⟶ Some open-source repositories and deployments were taken offline or disabled temporarily for security remediation.
⟶ Companies or projects relying on these systems suffered reputation damage, and had to regenerate or redesign security architectures.
⟶ A broader consequence: the assumption that “open source = transparent + safe by default” was challenged. The idea that open-source AI systems were inherently trustworthy came under scrutiny.
4.3 Lessons from the Field: What These Cases Reveal
These two incidents — one aimed at society and the other at systems — show a similar failure: inadequate intelligence protection. Whether a deepfake eroding democracy or a prompt injection damaging infrastructure, AI misuse proliferates where there are no “AI guardrails.”
⟶ deepfake detection is not just an investigative device; it is a democracy device.
⟶ “Prompt injection countermeasures” is not a developer’s add-on; it is a defense line.
⟶ And AI system abuse guardrails are not factors of comfort; they are factors of requirement in a world of intelligence which can be copied, perverted and amplified.
The future belongs, not to those who build the most powerful AI, but to those who build the safest AI.
5. Building AI guardrails: General Solutions for AI misuse and System Abuse
If the last section uncovered the cracks, this one reveals the scaffolding. AI guardrails are not just digital walls, they are intelligent systems that think, reason and grow along with the models they protect. They are the ethical, technical and procedural bedrock of responsible AI deployment.
And in the same way that roads require traffic lights, ecosystems of AI require guardrails that prevent speed from devolving into chaos. They don’t inhibit innovation, but refine it, directing brainpower toward human safety and societal trust.
Let us examine how a multi-layered architecture of "guardrails against misuses of AI systems" might contain misuse before it leaks and restore integrity to our digital ecologies.
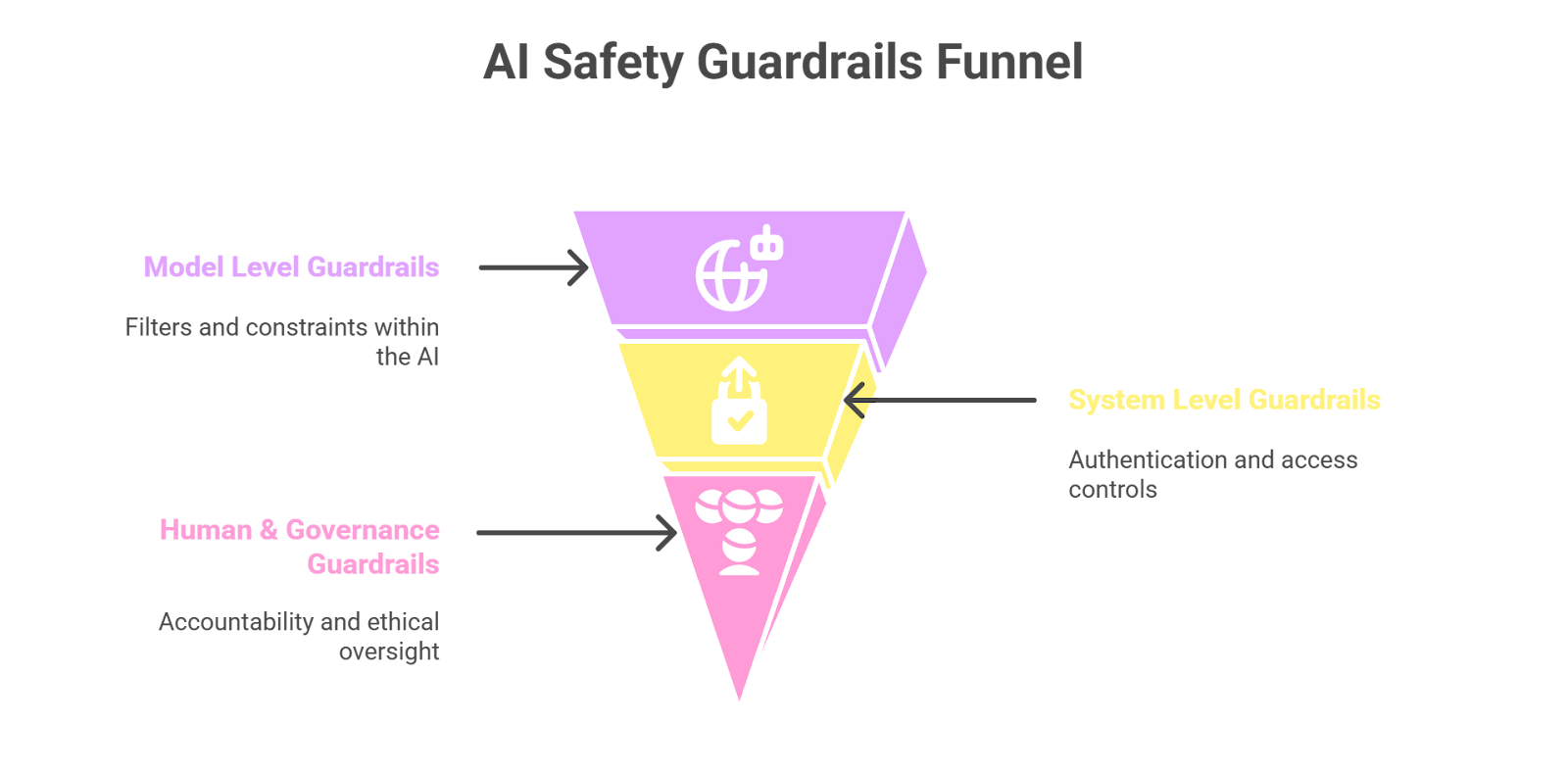
5.1 Multi-Layered AI guardrails Architecture
Envision AI safety as a multi-floor skyscraper, where each floor represents a progressive security layer. While no layer is infallible, they produce resiliency in aggregation.
Model Level Guardrails:
These guardrails are incorporated into the AI, such as filters for safe outputs, constraints on reinforcement learning and models that detect toxicity that prevents harmful or manipulative responses.
System Level Guardrails:
These operate in and around the AI, such as authentication procedures, sandboxing procedures, rate controls and restricted access controls to prevent external manipulation or injecting malicious prompts.
Human & Governance (AI) Guardrails:
These represent accountability, oversight, and ethical auditing. With every automated decision, there should be a reasonable level of traceability from the decision to a human or policy layer that is responsible.
Together these three create what we call a “defense in depth,” a concept whereby if one control fails there is another that will protect against the breach.
By including AI guardrails at every stage of the design, creation and deployment process, the organizations will transform from a reactive containment model to a proactive safety model.
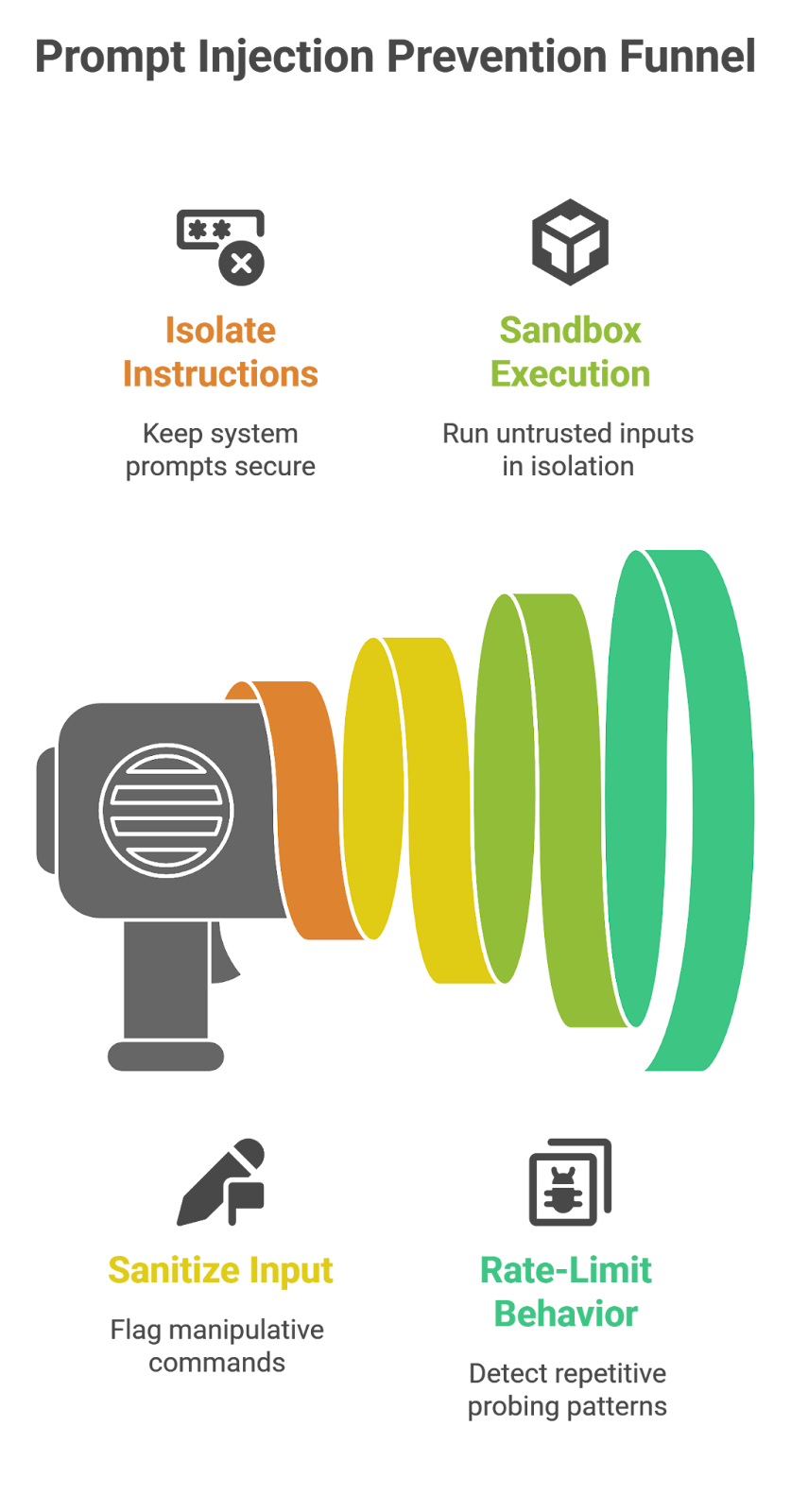
5.2 System Prompt Protection & prompt injection prevention
The 2025 open-source exploit illustrated just how damaging prompt injection can be. Attackers no longer have to break into databases — they can just “ask” models to expose themselves.
The prompt injection prevention guardrails mitigate this by:
Isolating sensitive instructions: Keeping system prompts encrypted or inaccessibly partitioned
Input sanitization: Regular expressions and semantic scanning to flag manipulative commands
Sandboxed query execution: Running untrusted inputs in isolated virtual environments
Rate-limiting & behavioral throttling: Detecting repetitive probing patterns (the signature of extraction attempts)
These guardrails effectively teach the AI to know when it is being tricked – a sort of meta-awareness that leads to discernment instead of compliance.
Had such guardrails been in place during the 2025 attacks, nearly all system prompt extraction attempts would have silently failed.
5.3 deepfake detection and Authenticity Guardrails
If prompt injection prevention protects the machines, then deepfake detection protects society.
AI impersonation and false media are foes to truth in the digital age. But technology can fight back.
The more sophisticated the way we put in the AI guardrails are:
⟶ Watermarking: the embedding of imperceptible cryptographic signatures therein the generated media.
⟶ Provenance tracking: The recording of content's creation history through platforms.
⟶ AI-fortified authenticity testing: the comparison of the visual, vocal and contextual clues to be tested against real world data already known.
Such AI guardrails could have prevented the 2024 Deepfake Election Incident, before it metamorphosed into the disaster it did. If the indicators of authenticity had been necessarily included in AI-generated audio, those fake "calls" would have been flagged (and deplatformed) in real time.
deepfake detection is not censorship. It is saving the truth. Without it, every sound and image would be a suspect.
5.4 Behavioral Monitoring and Anti-Spam Guardrails
In response to “AI misuse,” one of the least appreciated guardrails is ongoing behavioral analysis. Instead of examining the output of what the AI is saying, these systems use behavioral pattern analysis, and observe how often, quickly and when it is communicating.
For example:
⟶ If a chatbot suddenly starts creating thousands of messages per minute, that is not its capacity for “creativity” that people are trying to facilitate - it is recorded as “spam and malevolent content.”
⟶ If model outputs are now repeating emotionally manipulative language patterns across many session sample prints, it could be indicative of home that there could be social engineering attempts occurring.
Behavioral Intelligent Guardrails engage in pattern, tone and frequency aberrations: they are the immune systems of AI ecosystems.
When implemented in conjunction with the presently proposed rate limiting trigger and human escalation factors, these provide an adaptive guardrail being able to evolve as the behavioral tactics of AI misuse do.
5.5 Governance and Ethical Guardrails in AI Development
No technical system can operate to full potential without moral context. Governance-based AI guardrails promote a human-centered skills-approach technology, setting up the ethics that cannot be defined by the AI algorithms themselves.
Preferred practice:
⟶ Ethical AI audits: Routine evaluations of bias, privacy and misuse issues.
⟶ Transparency reports: Publicly available information of behaviors, limitations and failures of the AI Models.
⟶ Access tiered safety models: High risk capability allocated to verified source entities who are accountable.
Ultimately the AI guardrails are not patches into the advanced AI systems, - they are a philosophy; a philosophy of thought that specifies that Intelligence needs rules, it cannot just be let go forth.
6. Applying Guardrails to Real-World AI Misuse Cases
The strength of AI guardrails isn’t just in theory — it’s in how they respond under pressure.
Let’s return to the two incidents that exposed the vulnerabilities of modern AI ecosystems and imagine how things would have unfolded if proper guardrails had been in place.
6.1 Guardrails Applied to the 2024 Deepfake Election Incident
The 2024 Deepfake Election Incident was more than a scandal—it was a wake-up call. It demonstrated how AI misuse has the potential to erode trust on a national level. But it also provided an opportunity to showcase how AI system abuse guardrails could have made a difference.
Here’s how:
- deepfake detection guardrails:
⟶ Advanced systems for deepfake detection could have located the fake audio signatures as quickly as minutes after initial circulation.
⟶ Multi-platform AI content verification APIs could identify any media showing no verified provenance and flag it immediately for review.
2. Authenticity Watermarking:
⟶ If AI impersonation tools had to embed digital watermarks (traceable cryptographic signatures) in their work, platforms like X or TikTok would have had the option to auto-flag it before it went viral.
⟶ This would also have allowed fact-checkers and journalists to prove falsification immediately.
3. Behavioral Guardrails:
⟶ Automated monitoring could have determined unusual patterns—a large number of identical calls coming from unknown sources—which could have enabled early intervention.
4. Governance Guardrails:
⟶ Clearly defined legal frameworks requiring AI guardrails outlining procedures involving political content could have led to stricter authentication “guardrails” during election seasons.
The Outcome (if guardrails existed):
In place of chaotic reaction times, we would see proactive containment.
The fake audio would have been quarantined in hours, not days. The voters could have received authentic corrections from government sources, and the entire story could have turned around before the erosion of trust began.
In a word, deepfake detection and authenticity guardrails would have turned a national scandal into a case study in how responsible AI could be responsibly governed.
6.2 Guardrails Applied to the 2025 Prompt Injection Exploits
If the Deepfake Event was a social harm, the prompt injection exploits of 2025 were attacks on the system itself. Exposed is how hijacked from the inside area even open, transparent AI platforms. But the AI system abuse guardrails could have neutralized the breach.
And here is what it would have happened instead:
1. Systems with prompt injection prevention:
⟶ Advanced input sanitization could have filtered malignant prompt patterns (eg. “ignore all previous instructions”) before they hit the model.
⟶ Contextual AI guardrails: any queries attempting to breach system instructions might have been flagged.
2. Sandboxed Execution Environments:
⟶ User sessions isolated from the master logic of the model ensure that if even one instance is compromised, the rest remain uncolored.
3. Rate-Limiting or even Behavior Monitoring:
⟶ When a user generates repeated attempts through manipulative prompts, guardrails can impose an automated cooldown period where no further generative stimulus may act, or even human review modalities.
⟶ The above would have detected exploitation behavior long before exploitative exposure of sensitive data results.
4. Governance Guardrails:
⟶ Developers of open-source could have devised a reporting framework for AI misuse, so the community could explain and joint-associate vulnerabilities — converting crowdsourced knowledge into collective will via guard-rails.
Outcome (had Guardrails existed):
The hacks would have been detected within moments. Sensitive data would remain untouched: developer trust maintained, accountability preserved, transparency of product assured without compromise of safety.
Instead of a worry-some tale, a victory tale — proof that AI guardrails do not create restrictiveness into innovation they southerly safeguard it.
6.3 The Broader Impact: What These Scenarios Teach Us
Through all this comparison, emerges this iterance: "abuse of A.I." only can be perpetrated in vacant spaces.
⟶ When there exists AI guardrails, abuse becomes an event on the board to be counted, not an epidemic of invisibility.
⟶ When deep fake identification is established as a commodity, disinformation becomes an enterprise of temporary proportions and not contagious.
⟶ When prompt injection defenses are incorporated, systems and programs become a technical impossibility.
Every strip of Guardrails as to technical, behavioral, and ethical, is not a wall or hour glass, but a mirror, where it reflects abuse before it ascends. In a time when artificial intelligence can simulate anything, the factor of authenticity becomes our present bulwark.
7. Beyond Technology: The Ethical Dimension of AI Misuse Prevention
When talking about "misuse of AI ", it’s easy to get drawn to code, firewalls or algorithms — the physical elements of the system. But any misuse case begins not in a data centre but in human intention.
Behind every ... deepfake, every prompt injection, and every synthetic manipulation is a person (or persons) who has chosen to arm intelligence. This is why AI guardrails are not merely lines of defense, they are lines of ethics.
They represent a collective decision to determine the manner in which Intelligence should behave, and by extension how humanity should wield it.
7.1 Ethics as the Ultimate AI Guardrail
Technology is quick, but ethics is its direction. Without moral guidance, innovation can gain the momentum of indifference.

Here’s what ethical guardrails along the lines of “AI system abuse” must mean:
⟶ Transparency: every AI system should disclose when users are interfacing with non-human intelligence: a direct antidote to the "AI imposter" perils.
⟶ Accountability: when harm is done by AI created content the onus of remedy must repossess itself upon some developer, organization, governance group, etc.
⟶ Equity: guardrails must be deployed to safeguard that the prevention of abuse does not become an instance of over-reach, due, perhaps, to excessive concern for security and perfect individual liberty.
⟶ Worldwide Cooperation: localisation is negligent. Abuses do not discriminate relative to national bounding. The production of deep fakes in a national context can lead to the influencing of voters in other countries. An ethical AI framework must therefore transcend local application and become ennobled with the stamp of international quality.
Ethics in AI isn’t a checkbox — it’s a compass. It ensures that even as intelligence scales, conscience scales with it.
7.2 Human-in-the-Loop: Restoring Trust in Intelligent Systems
No amount of advanced AI guardrails can effectively replace sound human judgment. In fact, the most effective safeguarding systems are human-in-the-loop — combining the precision of automation with the perspective of empathy.
When the AI identifies the possibility of misuse, it should elevate it for human review. When disinformation rapidly propagates, human moderators must appreciate the nuances that the algorithms miss. When systems evolve, ethicists must probe the questions of “why?”
This balancing game — of man vs. machine — is the ultimate safeguard against “AI misuse.” Because in the end, it’s not the horsepower of the processor that separates the control of chaos. It’s the moral horsepower.
8. Conclusion
AI has shown us what humankind will achieve by the magnification of intelligence — it has also shown us what will be done when the exercise of power exceeds the application of principles.
The task before us is not to arrest progress, but to steer it — to see that the shape of the new engines we build shall conform to the ideals we hold.
Human "mal-uses" of "AI" will never vanish. Just as violation of law exists in every city, and need ever be expected to exist, so should there be prodding at lawlessness in every engine we construct. But with adequate provision for "AI guard-rails," it can be assured affirmative that they will be confined to incidence, traceability and containability, instead of disaster-flight.
Guard-rails do not impede movement — they define its character. They provide the invisible structure of safety, the invisible code of rules which keeps the thing constructed from chaos.
And just at the present juncture when we find the machinery of thought, speech and decision, we need to choose a canon by which to gauge the exercises of every maker of tools, statesman and citizen alike.
The canon is this: that the criterion of the pattern of intelligent living is not what it can do, but what it will not do.
In that limit of intelligence is thoughtful reflection.
In the agreement of this thought lies the use of the intellect.
In the "AI guard-rails" discovered in this journey is trust.






Protect your AI with WizSumo — deploy layered guardrails that stop misuse and preserve trust!

.png)
.png)
.png)



